
3D Aware Region Prompted Vision Language Model
Anonymous Submission 669
Anonymous Submission 669
A key idea of SR-3D is the introduction of a canonical positional representation shared across single-view and multi-view inputs. This unified representation enables large-scale single-view pretraining and supports the transfer of learned spatial priors to multi-view settings.
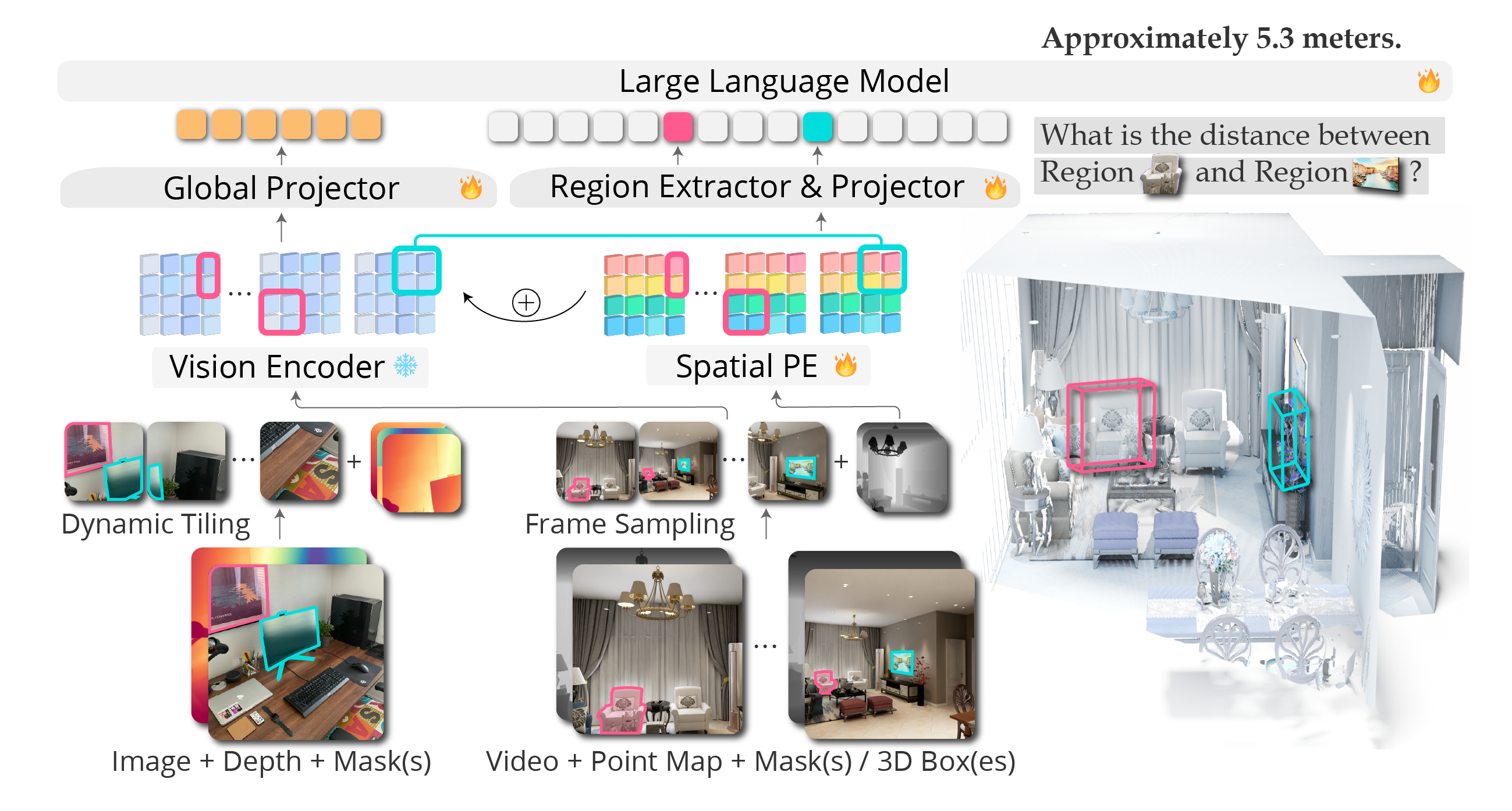
Incorporating 3D positional information improves spatial understanding in single-view models; comparing to the base model NVILA-Lite-8B, SR-3D achieves higher spatial performance.

